字符串
字符串是以''或""括起来的任意文本;
Python 转义字符
- 字符串内部既包含
'又包含"时,可以用转义字符\来标识
在需要在字符中使用特殊字符时,python用反斜杠()转义字符。如下表:
| 转义字符 | 描述 |
|---|---|
\(在行尾时) |
续行符 |
| \' | 单引号 |
| \" | 双引号 |
| \a | 响铃 |
| \b | 退格(Backspace) |
| \e | 转义 |
| \000 | 空 |
| \n | 换行 |
| \v | 纵向制表符 |
| \t | 横向制表符 |
| \r | 回车 |
| \f | 换页 |
| \oyy | 八进制数,yy代表的字符,例如:\o12代表换行 |
| \xyy | 十六进制数,yy代表的字符,例如:\x0a代表换行 |
| \other | 其它的字符以普通格式输出 |
- Python 允许用
r''表示''内部的字符串默认不转义
python 格式化字符串
- 常见的占位符有:
| 占位符 | 含义 |
|---|---|
| %d | 整数 |
| %f | 浮点数 |
| %s | 字符串 |
| %x | 十六进制整数 |
- 如果不太确定应该用什么,永远用
%s
>>> 'Age: %s. Gender: %s' % (25, True)
'Age: 25. Gender: True'
- 有些时候,字符串里面的 % 是一个普通字符,需要转义:用%%来表示一个%:
>>> 'growth rate: %d %%' % 7 'growth rate: 7 %'
编码
ASCII & Unicode & UTF-8 占用字节对比
- ASCII 编码是 1 个字节;
- Unicode 编码通常是 2 个字节;
- UTF-8编码 是「可变长编码」它把一个 Unicode 字符根据不同的数字大小编码成 1-6 个字节。常用的英文字母被编码成 1 个字节,汉字通常是 3 个字节,只有很生僻的字符才会被编码成 4-6 个字节
- 举个例子:
| 字符 | ASCII | Unicode | UTF-8 |
|---|---|---|---|
| A | 01000001 | 00000000 01000001 | 01000001 |
| 中 | (无) | 01001110 00101101 | 11100100 10111000 10101101 |
ASCII & Unicode & UTF-8 转换
1. ASCII 编码中字符串与数字的转换
Python 的诞生比 Unicode 标准发布的时间还要早,所以最早的 Python 只支持 ASCII 编码,普通的字符串'ABC'在 Python 内部都是 ASCII 编码的
其中,字符串与数字通过 ord() 和 chr() 方法转换
>>> ord('A')
65
>>> chr(65)
'A'
2. Unicode & UTF-8 转换
一般在程序内通用 Unicode 编码,在程序外通用 UTF-8 编码。
- 举个例子:
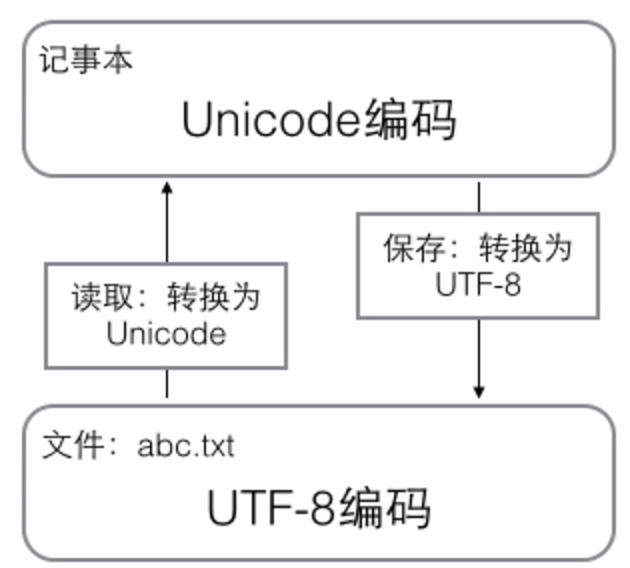
用记事本编辑的时候,从文件读取的UTF-8字符被转换为Unicode字符到内存里,编辑完成后,保存的时候再把Unicode转换为UTF-8保存到文件
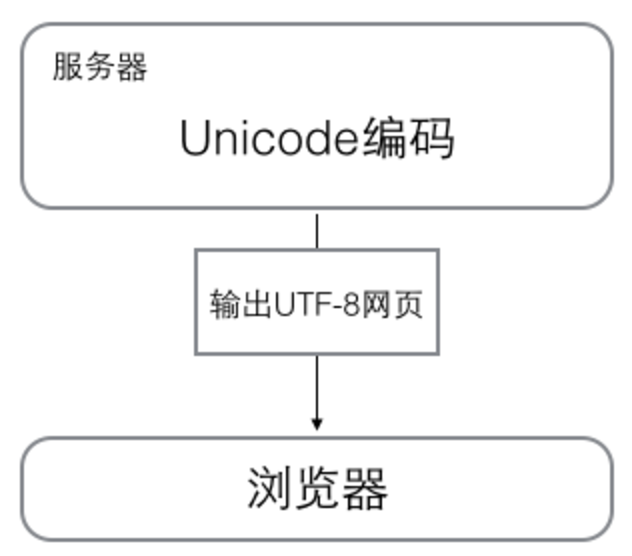
浏览网页的时候,服务器会把动态生成的Unicode内容转换为UTF-8再传输到浏览器
Unicode 转换为 UTF-8 用
encode('utf-8')方法英文字符转换后表示的UTF-8的值和Unicode值相等(但占用的存储空间不同),而中文字符转换后1个Unicode字符将变为3个UTF-8字符
>>> u'ABC'.encode('utf-8') 'ABC' >>> u'中文'.encode('utf-8') '\xe4\xb8\xad\xe6\x96\x87' >>> len(u'ABC') 3 >>> len('ABC') 3 >>> len(u'中文') 2 >>> len('\xe4\xb8\xad\xe6\x96\x87') 6
UTF-8转换为Unicode,用decode('utf-8')方法
>>> 'abc'.decode('utf-8') u'abc' >>> '\xe4\xb8\xad\xe6\x96\x87'.decode('utf-8') u'\u4e2d\u6587' >>> print '\xe4\xb8\xad\xe6\x96\x87'.decode('utf-8') 中文python 文件制定编码和解释器
通常在 python 文件开头加下面两行
#!/usr/bin/env python
# -*- coding: utf-8 -*-
第一行注释是为了告诉Linux/OS X系统,这是一个Python可执行程序,Windows系统会忽略这个注释
第二行注释是为了告诉Python解释器,按照UTF-8编码读取源代码,否则,你在源代码中写的中文输出可能会有乱码。
由于 Python 源代码也是一个文本文件,所以,当源代码中包含中文的时候,在保存源代码时,就需要务必指定保存为UTF-8编码。